Paper Review - Moshi: A Speech-Text Foundation Model for Real-Time Dialogue
Review of the Paper: Moshi: A Speech-Text Foundation Model for Real-Time Dialogue
Paper Link: arXiv:2410.00037
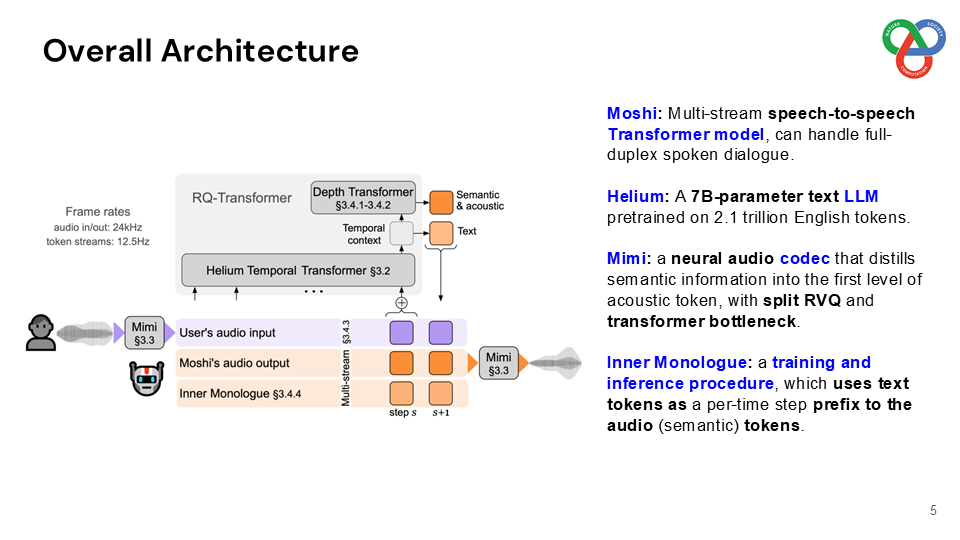
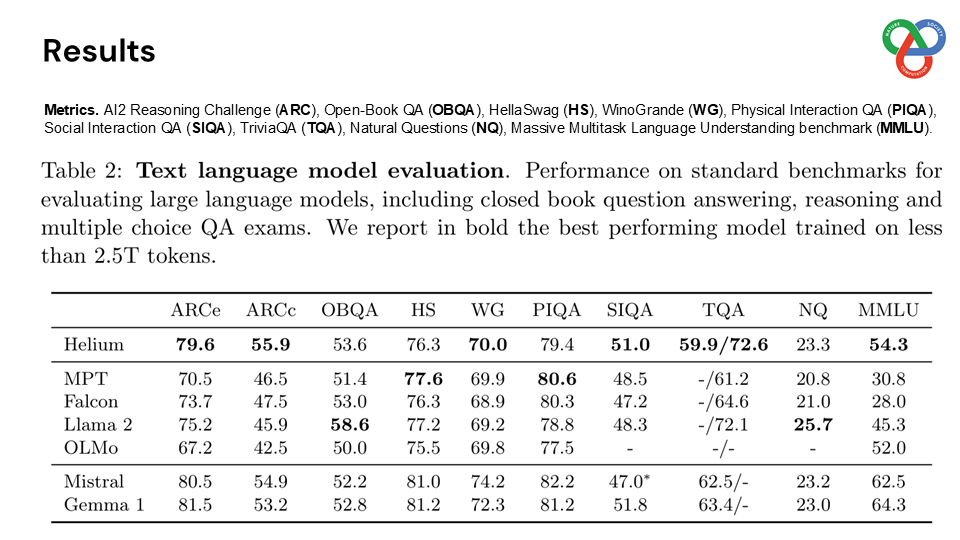
This paper presents a novel framework for real-time, full-duplex spoken dialogue, enabling simultaneous listening and speaking capabilities in a conversational speech AI model. Traditional frameworks rely on separate modules such as voice activity detection, speech recognition, dialogue management, and text-to-speech, which result in high latency and rigid turn-taking that cannot emulate natural conversation dynamics. Moshi approaches these challenges holistically by framing spoken dialogue as a speech-to-speech generation.
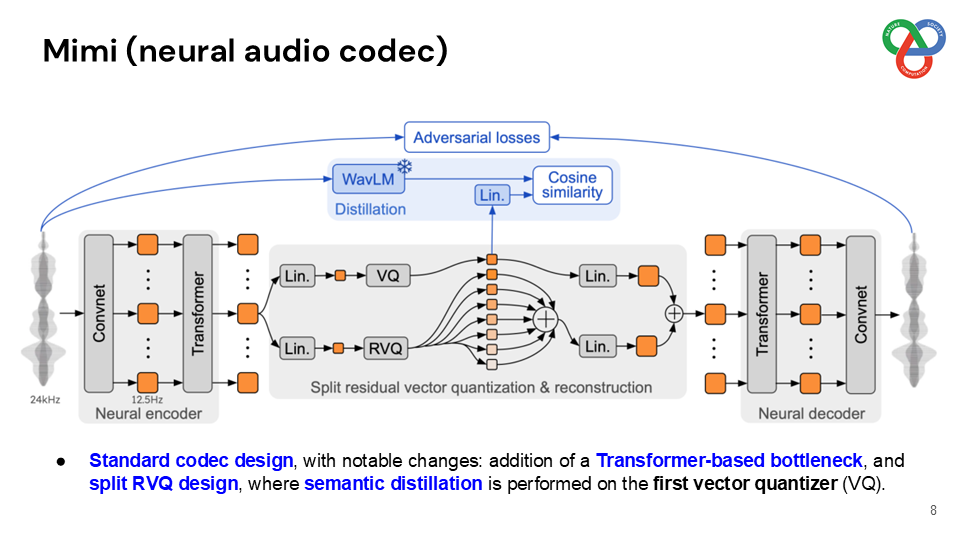
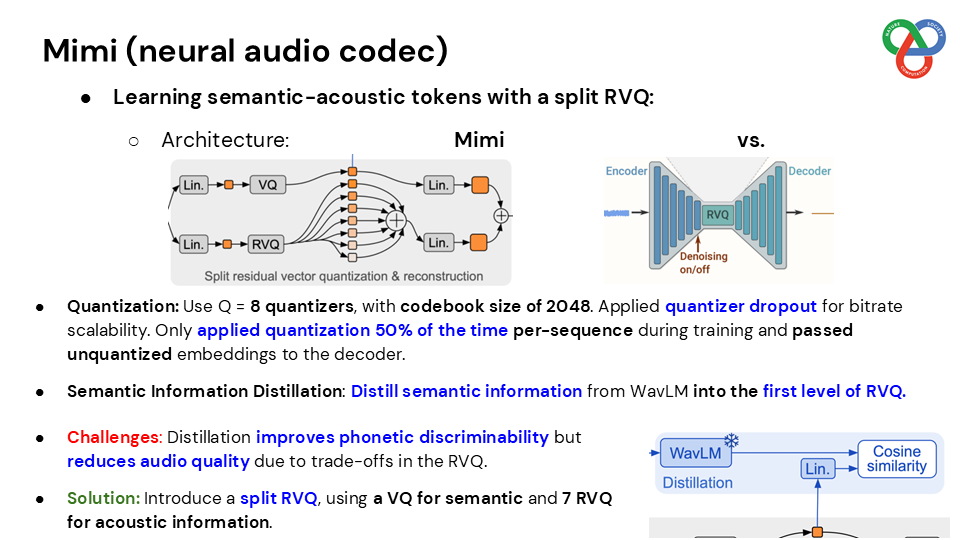
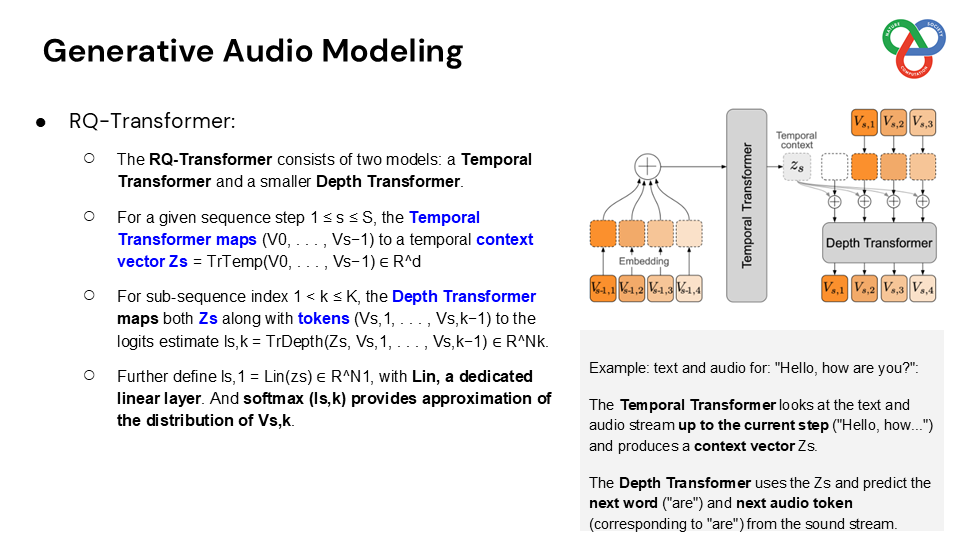
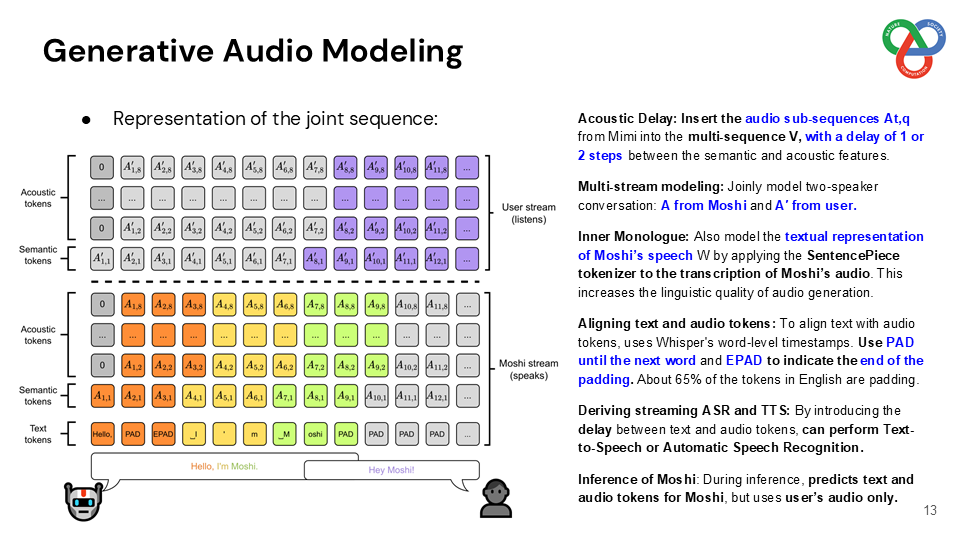
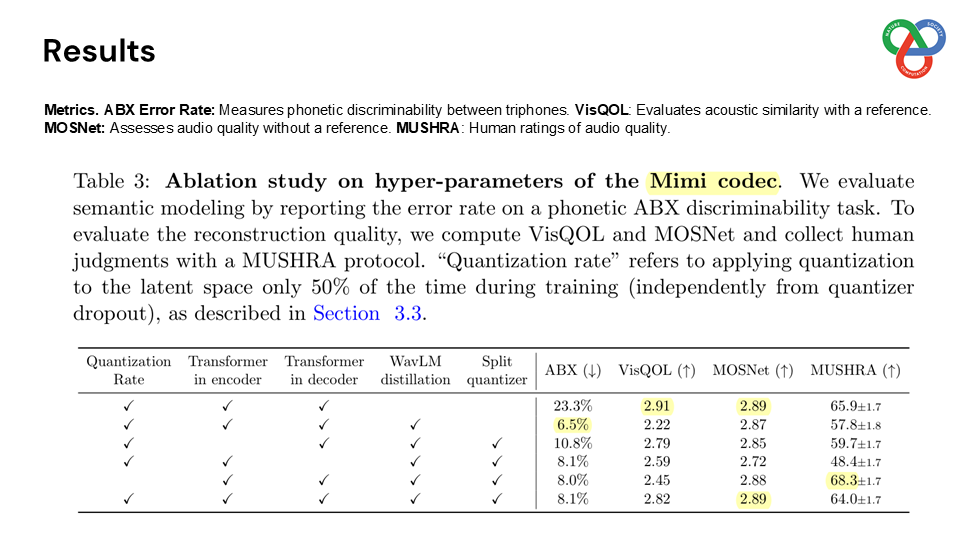
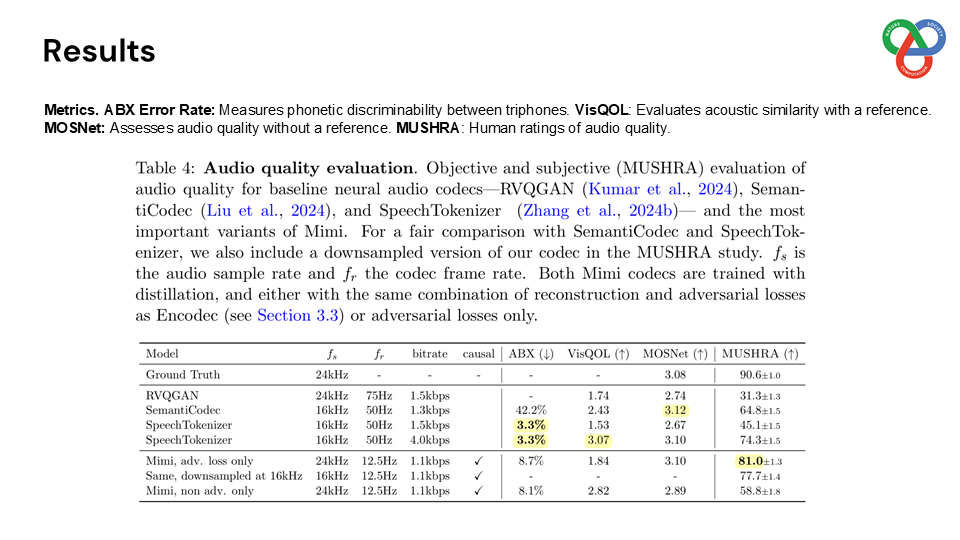
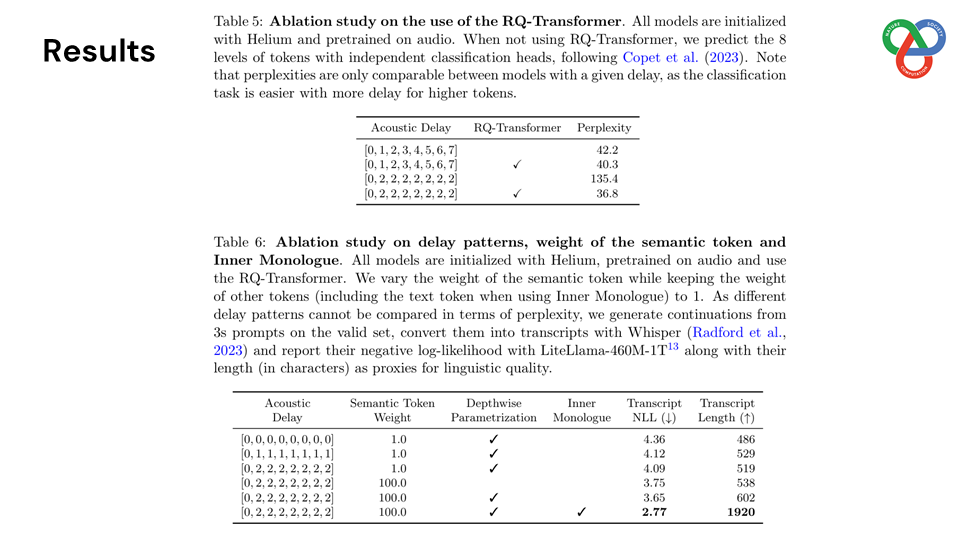
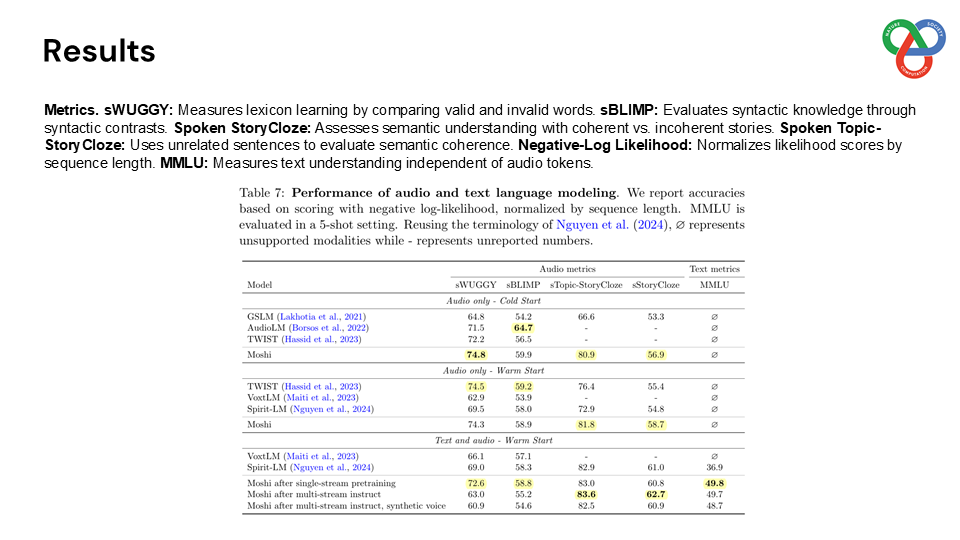
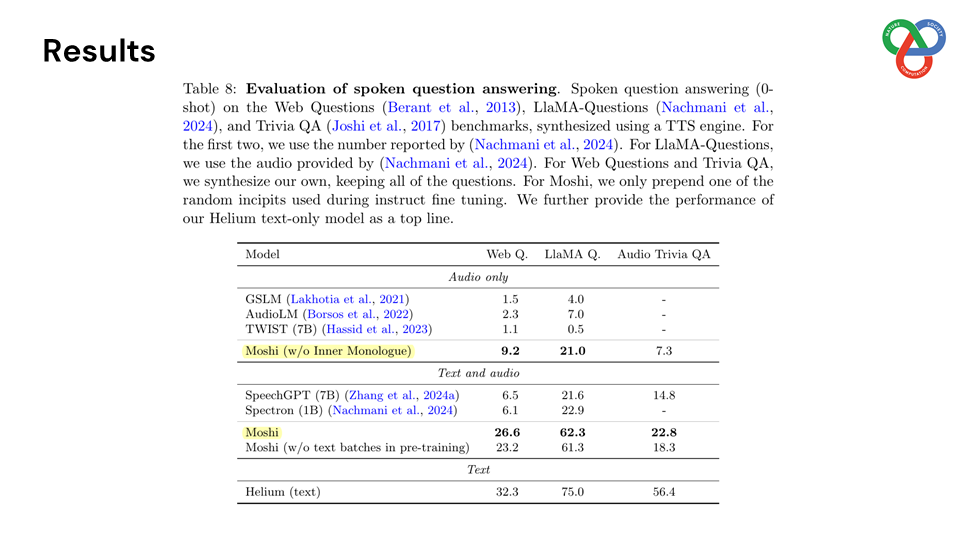
Built on a language model backbone, Moshi generates speech tokens directly from an audio codec, modeling both the user’s and system’s speech in parallel streams. This architecture removes the need for explicit speaker turns, allowing for fluid conversational dynamics. Additionally, Moshi incorporates a technique called “Inner Monologue,” which predicts text tokens as a prefix to audio tokens, enhancing the linguistic quality of generated speech while supporting real-time streaming for speech recognition and synthesis.
I presented this paper at CCDS, IUB, where it led to discussions on Moshi’s architecture and its potential applications in interactive speech AI. The presentation slides are shared below.
Presentation Slides: Link to slides