publications
2025
- EMNLP 2025
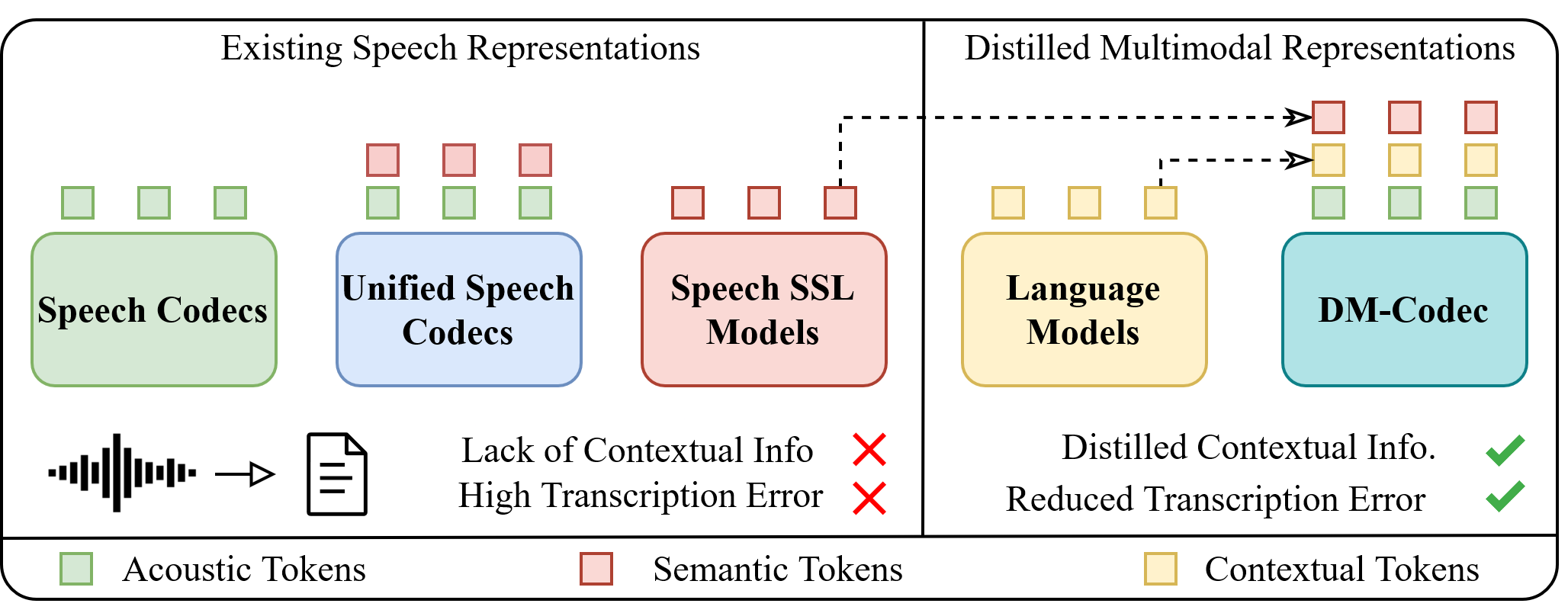 DM-Codec: Distilling Multimodal Representations for Speech TokenizationMd Mubtasim Ahasan, Md Fahim, Tasnim Mohiuddin, A K M Mahbubur Rahman, Aman Chadha, Tariq Iqbal, M Ashraful Amin, Md Mofijul Islam, and Amin Ahsan AliIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025
DM-Codec: Distilling Multimodal Representations for Speech TokenizationMd Mubtasim Ahasan, Md Fahim, Tasnim Mohiuddin, A K M Mahbubur Rahman, Aman Chadha, Tariq Iqbal, M Ashraful Amin, Md Mofijul Islam, and Amin Ahsan AliIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025Recent advancements in speech-language models have yielded significant improvements in speech tokenization and synthesis. However, effectively mapping the complex, multidimensional attributes of speech into discrete tokens remains challenging. This process demands acoustic, semantic, and contextual information for precise speech representations. Existing speech representations generally fall into two categories: acoustic tokens from audio codecs and semantic tokens from speech self-supervised learning models. Although recent efforts have unified acoustic and semantic tokens for improved performance, they overlook the crucial role of contextual representation in comprehensive speech modeling. Our empirical investigations reveal that the absence of contextual representations results in elevated Word Error Rate (WER) and Word Information Lost (WIL) scores in speech transcriptions. To address these limitations, we propose two novel distillation approaches: (1) a language model (LM)-guided distillation method that incorporates contextual information, and (2) a combined LM and self-supervised speech model (SM)-guided distillation technique that effectively distills multimodal representations (acoustic, semantic, and contextual) into a comprehensive speech tokenizer, termed DM-Codec. The DM-Codec architecture adopts a streamlined encoder-decoder framework with a Residual Vector Quantizer (RVQ) and incorporates the LM and SM during the training process. Experiments show DM-Codec significantly outperforms state-of-the-art speech tokenization models, reducing WER by up to 13.46%, WIL by 9.82%, and improving speech quality by 5.84% and intelligibility by 1.85% on the LibriSpeech benchmark dataset.
- Preprint
 FuseCodec: Semantic-Contextual Fusion and Supervision for Neural CodecsMd Mubtasim Ahasan, Rafat Hasan Khan, Tasnim Mohiuddin, Aman Chadha, Tariq Iqbal, M Ashraful Amin, Amin Ahsan Ali, Md Mofijul Islam, and A K M Mahbubur RahmanSep 2025
FuseCodec: Semantic-Contextual Fusion and Supervision for Neural CodecsMd Mubtasim Ahasan, Rafat Hasan Khan, Tasnim Mohiuddin, Aman Chadha, Tariq Iqbal, M Ashraful Amin, Amin Ahsan Ali, Md Mofijul Islam, and A K M Mahbubur RahmanSep 2025Speech tokenization enables discrete representation and facilitates speech language modeling. However, existing neural codecs capture low-level acoustic features, overlooking the semantic and contextual cues inherent to human speech. While recent efforts introduced semantic representations from self-supervised speech models or incorporated contextual representations from pre-trained language models, challenges remain in aligning and unifying the semantic and contextual representations. We introduce FuseCodec, which unifies acoustic, semantic, and contextual representations through strong cross-modal alignment and globally informed supervision. We propose three complementary techniques: (i) Latent Representation Fusion, integrating semantic and contextual features directly into the encoder latent space for robust and unified representation learning; (ii) Global Semantic-Contextual Supervision, supervising discrete tokens with globally pooled and broadcasted representations to enhance temporal consistency and cross-modal alignment; and (iii) Temporally Aligned Contextual Supervision, strengthening alignment by dynamically matching contextual and speech tokens within a local window for fine-grained token-level supervision. We further introduce FuseCodec-TTS, demonstrating our methodology’s applicability to zero-shot speech synthesis. Empirically, FuseCodec achieves state-of-the-art performance in LibriSpeech, surpassing EnCodec, SpeechTokenizer, and DAC in transcription accuracy, perceptual quality, intelligibility, and speaker similarity. Results highlight the effectiveness of contextually and semantically guided tokenization for speech tokenization and downstream tasks.
- Preprint
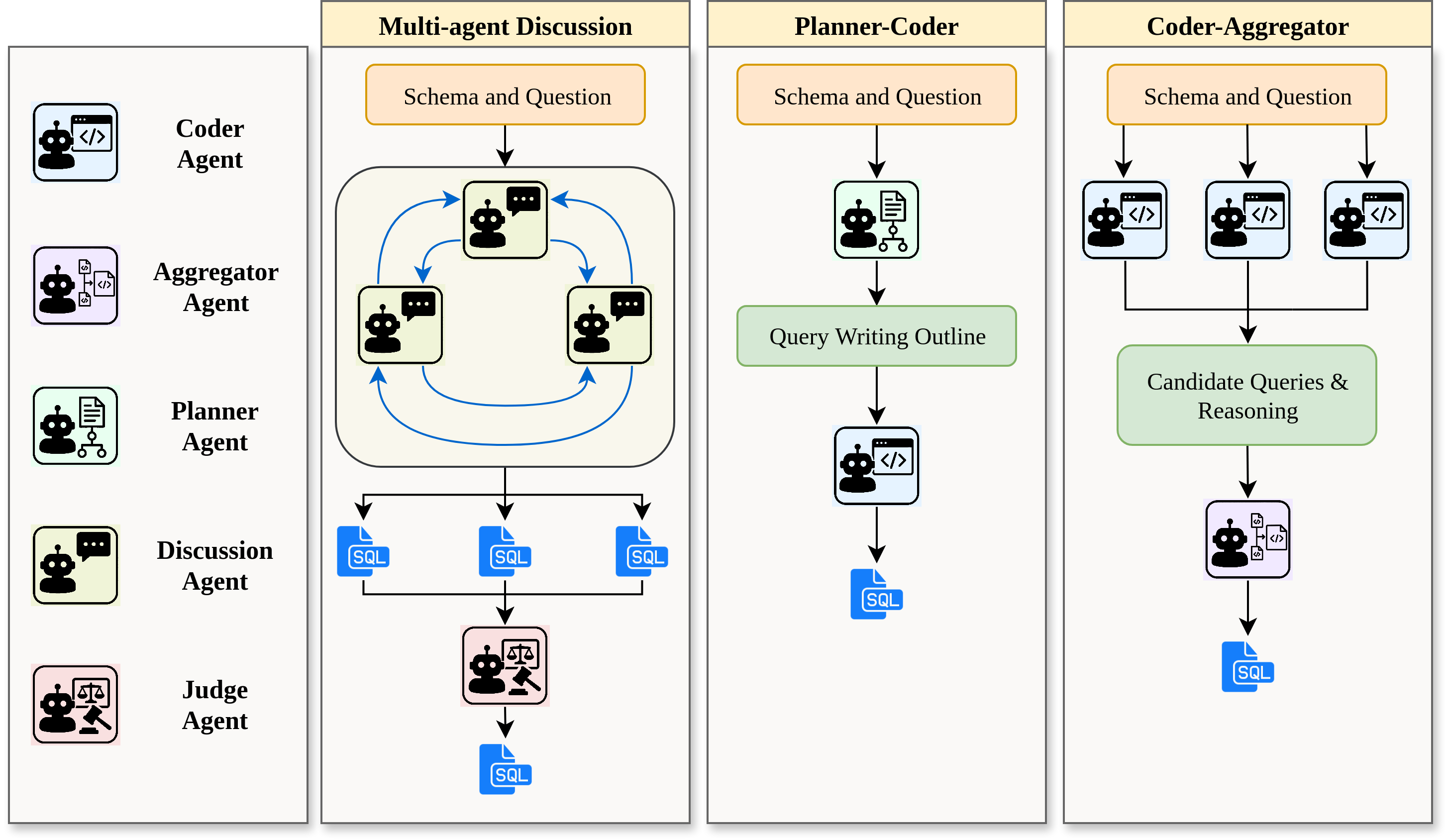 BAPPA: Benchmarking Agents, Plans, and Pipelines for Automated Text-to-SQL GenerationFahim Ahmed, Md Mubtasim Ahasan, Jahir Sadik Monon, Muntasir Wahed, M Ashraful Amin, A K M Mahbubur Rahman, and Amin Ahsan AliNov 2025
BAPPA: Benchmarking Agents, Plans, and Pipelines for Automated Text-to-SQL GenerationFahim Ahmed, Md Mubtasim Ahasan, Jahir Sadik Monon, Muntasir Wahed, M Ashraful Amin, A K M Mahbubur Rahman, and Amin Ahsan AliNov 2025Text-to-SQL systems provide a natural language interface that can enable even laymen to access information stored in databases. However, existing Large Language Models (LLM) struggle with SQL generation from natural instructions due to large schema sizes and complex reasoning. Prior work often focuses on complex, somewhat impractical pipelines using flagship models, while smaller, efficient models remain overlooked. In this work, we explore three multi-agent LLM pipelines, with systematic performance benchmarking across a range of small to large open-source models: (1) Multi-agent discussion pipeline, where agents iteratively critique and refine SQL queries, and a judge synthesizes the final answer; (2) Planner-Coder pipeline, where a thinking model planner generates stepwise SQL generation plans and a coder synthesizes queries; and (3) Coder-Aggregator pipeline, where multiple coders independently generate SQL queries, and a reasoning agent selects the best query. Experiments on the Bird-Bench Mini-Dev set reveal that Multi-Agent discussion can improve small model performance, with up to 10.6% increase in Execution Accuracy for Qwen2.5-7b-Instruct seen after three rounds of discussion. Among the pipelines, the LLM Reasoner-Coder pipeline yields the best results, with DeepSeek-R1-32B and QwQ-32B planners boosting Gemma 3 27B IT accuracy from 52.4% to the highest score of 56.4%.


